流式语音合成
流式语音合成
请求方式
WebSocket
请求地址
api.stepfun.com/v1/realtime/audio
请求头
Authorizationstringrequired
鉴权使用的 KEY,其值为Bearer STEP_API_KEY
请求参数
modelstringrequired
需要使用的模型名称,当前仅支持step-tts-2、step-tts-mini和step-tts-vivid。
调用说明
流式生成音频需要在服务链接成功后,发送对应的 Client Event 事件,获取对应的 Server Event ,来完成音频的生成。
Client Event & Server Event 对应关系
以下为流式调用过程中,客户端发送的 Client Event 事件及服务端返回的 Server Event 事件。
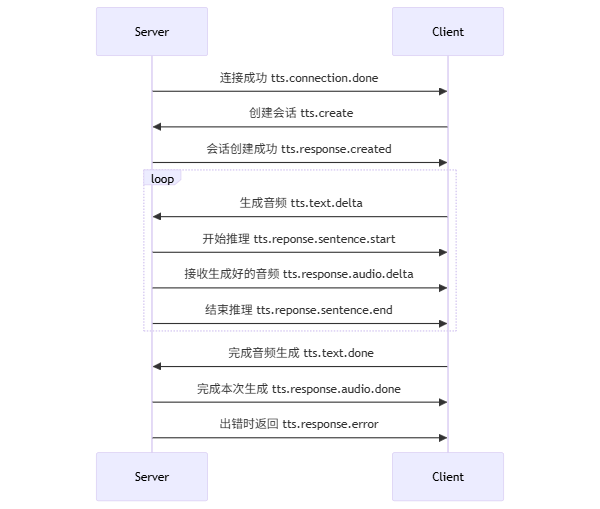
详细描述可参考下方的详细说明。
| 消息类型 | 客户端发送 | 服务端返回 | 备注 |
|---|---|---|---|
| 建联成功 | - | tts.connection.done | WebSocket 链接成功后下发的事件 |
| 创建会话 | tts.create | tts.response.created | 创建会话及对应响应。收到对应响应后,可进行进一步生成。 |
| 开始生成单句 | tts.response.sentence.start | 累计的文本满足生成条件,开始生成 | |
| 发送文本 | tts.text.delta | tts.response.audio.delta | 创建文本及对应的响应,收到响应后即可进行播放。 |
| 结束生成单句 | tts.response.sentence.end | 累计的文本满足生成条件,结束生成 | |
| 清空缓冲区 | tts.text.flush | tts.text.flushed | 可快速清空缓冲区,一次性获得当前尚未返回的音频内容。 |
| 发送文本结束 | tts.text.done | response.audio.done | 完成本次生成 ,不再生成,服务端将会释放连接。 |
| 音频生成出错 | - | tts.response.error | 在生成过程中出现错误时的事件 |
如果连续 60 秒无动作,则系统会自动断开链接。
Client Event 详细说明
创建会话 tts.create
创建会话的事件,在完成建联后,收到 tts.connection.done Server Event 返回后发送此事件开始生成音频。
-
typestringrequired
固定为tts.create -
dataobjectrequired
事件内容-
session_idstringrequired
会话 ID,可用于判断具体沟通是哪个会话,由tts.connection.done事件返回。 -
voice_idstringrequired
音色 ID,必填,可参考 音色列表 查看支持的音色,试听对应音色。 -
response_formatstringoptional
音频格式,支持 [“wav”, “mp3”, “flac”, “opus”,“pcm”],非必填,默认 mp3 -
sample_rateintoptional
采样率,可选项为8000,16000,22050,24000,默认值为24000。 -
pronunciation_mapobject arrayoptional
定义某个文字或符号注音或发音替换规则,在中文文本中,声调用数字表示:一声为1,二声为2,三声为3,四声为4,轻声为5。注:step-tts-vivid 模型暂不支持该字段。tonestringrequired
具体发音映射规则,以“/”隔开,示例:["绯闻/fei1闻","扁舟/偏舟","嫉妒/ji2妒"]
-
speed_ratiofloatoptional
语速,取值范围为 0.5~2,默认值 1.0。0.5 表示 0.5 倍速。 -
volume_ratiofloatoptional
音量,取值范围为 0.1~2.0,默认值 1.0。0.1 表示缩小至 10% 音量;2.0 表示扩大至 200%音量 -
modestringoptional
生成模式,可选项为sentence和default。default表示按字生成,适合大模型流式生成场景,sentence表示按句生成,适合已经生成好完整句子。默认为default。 -
voice_labelobjectoptional
音色标签,使用自定义音色时需要传入。language、emotion 和 style 三个自动同时只能有一个字段有值,暂不支持多个组合。
-
default 模式适用于 TTS 和大语言模型组合使用,该模式会自动进行攒句和切句,因此不会马上返回而内容,而是当用户的输入满足一句话时才会进行生成;如果需要强制返回,则可以发送 tts.text.flush,模型则可快速返回内容。
sentence 模式适用于已经有现成的长文本的场景,该模式会自动基于。!?!?进行切句,并进行生成。
Example
{
"type": "tts.create",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"voice_id": "cixingnansheng",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000,
"pronunciation_map":{
"tone":[
"阿胶/e1胶",
"扁舟/偏舟",
"LOL/laugh out loudly"
]
}
}
}生成音频 tts.text.delta
生成音频的 Client Event。
在生成过程中,如果 TTS 引擎认为已经达成了生成的条件,则会返回 tts.response.sentence.start
声明开始推理,并返回1个或多个 tts.response.audio.delta,返回音频内容。并在音频内容返回完成后,返回
tts.response.sentence.end 事件声明完成此句完成生成。如 TTS 引擎认为未达成生成的条件,则不会返回任何事件。
-
typestringrequired
固定为tts.text.delta -
dataobjectrequired
事件内容-
session_idstringrequired
会话 ID,可用于判断具体沟通是哪个会话,由tts.connection.done事件返回。 -
textstringrequired
要生成的文本内容,最大长度为 1000 个字符
-
Example
{
"type": "tts.text.delta",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text": "今天的天气真不错,我想去学习阶跃星辰的大模型技术"
}
}清空缓冲区 tts.text.flush
清空缓冲区,强制返回模型生成的音频。
-
typestringrequired
固定为tts.text.flush -
dataobjectrequired
事件内容session_idstringrequired
会话 ID,可用于判断具体沟通是哪个会话,由tts.connection.done事件返回。
{
"type": "tts.text.flush",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}完成音频生成 tts.text.done
完成音频生成
-
typestringrequired
固定为tts.text.done -
dataobjectrequired
事件内容session_idstringrequired
会话 ID,可用于判断具体沟通是哪个会话,由tts.connection.done事件返回。
{
"type": "tts.text.done",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}Server Event 详细说明
连接成功 tts.connection.done
连接成功
-
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。 -
typestringrequired
固定为tts.connection.done -
dataobjectrequired
事件内容session_idstringrequired
会话 ID,后续请求时需要带上使用
Example
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.connection.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70"
}
}会话创建成功 tts.response.created
会话创建成功
-
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。 -
typestringrequired
固定为tts.response.created -
dataobjectrequired
事件内容session_idstringrequired
会话 ID,后续请求时需要带上使用
Example
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.connection.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70"
}
}开始生成单句 tts.response.sentence.start
开始生成单句
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。typestringrequired
固定为tts.response.sentence.startdataobjectrequired
事件内容session_idstringrequired
会话 IDtextstringrequired
本次生成的文本内容started_atstringrequired
本次生成开始的时间,时间戳
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.sentence.start",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text":"blah blah",
"started_at":10292929292 # 时间戳
}
}接收生成好的音频 tts.response.audio.delta
接收生成好的音频
-
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。 -
typestringrequired
固定为tts.response.audio.delta -
dataobjectrequired
事件内容session_idstringrequired
会话 ID,后续请求时需要带上使用statusstringrequired
生成状态,可选项为unfinished和finished。unfinished表示生成未完成,finished表示生成完成。audiostringrequired
音频内容,BASE64 编码的音频内容durationfloatrequired
音频时长,单位为秒
{
"event_id": "42bd707a-ba16-4ddb-a751-54d84301b474",
"type": "tts.response.audio.delta",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0",
"status": "unfinished",
"audio": "BASE64 的音频内容",
"duration": 2.043375
}
}结束生成单句 tts.response.sentence.end
结束生成单句
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。typestringrequired
固定为tts.response.sentence.enddataobjectrequired
事件内容session_idstringrequired
会话 IDtextstringrequired
本次生成的文本内容ended_atstringrequired
本次生成结束的时间,时间戳
{
"event_id": "01956e73888c7953896a6e176bf3d760",
"type": "tts.response.sentence.end",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"text":"blah blah",
"ended_at":10292929292 # 时间戳
}
}开始清空缓存 tts.text.flushed
系统收到指令,开始清空缓存。
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。typestringrequired
固定为tts.response.audio.deltadataobjectrequired
事件内容session_idstringrequired
会话 ID,后续请求时需要带上使用
{
"event_id": "01956e8ee1b9788c95d5981b1cfdbf12",
"type": "tts.text.flushed",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0"
}
}完成本次生成 tts.response.audio.done
完成本次生成。接收此事件后,将会自动断开链接。此外当 IDLE 时长超过 60 秒,也会自动完成生成。
event_idstringrequired
事件 ID,用于标识本次请求,当联系客服获取支持时,可提供此 ID 协助排查问题。typestringrequired
固定为tts.response.audio.deltadataobjectrequired
事件内容session_idstringrequired
会话 ID,后续请求时需要带上使用audiostringrequired
音频内容,BASE64 编码的音频内容,包含所有音频的内容。
Example
{
"event_id": "01956e8bf5067d6499cdfa0dad34f805",
"type": "tts.response.audio.done",
"data": {
"session_id": "01956e7388477cfcbdc3aaabf364bc70",
"audio": ""
}
}故障报错 tts.response.error
当生成过程中出现问题后,将会返回此事件。
{
"event_id": "01956e8fdb157619a852bdf38028db45",
"type": "tts.response.error",
"data": {
"session_id": "01956e8dc1d77bb98f9da8d1b642fcf0",
"code": "503",
"message": "The engine is currently overloaded, please try again later",
"details": {
"error": "The engine is currently overloaded, please try again later"
}
}
}调用代码参考
先执行 pip install websocket rel 后执行如下代码。
import websocket
import rel
import json
headers = {
"Authorization": "" # 更新为你的 STEPFUN API KEY
}
def get_start_event(sid):
return json.dumps(
{
"type": "tts.create",
"data": {
"session_id": sid,
"voice_id": "cixingnansheng",
"response_format": "wav",
"volume_ratio": 1.0,
"speed_ratio": 1.0,
"sample_rate": 16000
},
}
)
def on_message(ws, message):
data = json.loads(message)
session_id = data["data"]["session_id"]
event_type = data["type"]
if event_type == "tts.connection.done":
start_event = get_start_event(session_id)
ws.send(start_event)
# 继续添加其他事件处理逻辑
print(message)
def on_error(ws, error):
print(error)
if __name__ == "__main__":
websocket.enableTrace(True)
ws = websocket.WebSocketApp(
"wss://api.stepfun.com/v1/realtime/audio?model=step-tts-mini",
header=headers,
on_message=on_message,
on_error=on_error,
)
ws.run_forever(
dispatcher=rel,
reconnect=5
)
rel.signal(2, rel.abort)
rel.dispatch()