目前推荐使用
step-1o-turbo-vision 模型。该模型拥有最强的视频理解能力,推荐默认开启 detail 模式。能力限制
- 目前
step-3.7-flash、step-1o-turbo-vision等模型支持 JPG/JPEG、PNG、静态 GIF、WebP 格式的图片,且支持通过 URL 或 Base64 作为参数传递。 - 上述模型限制了单次请求图像不能超过 60 张,如果超过 60 张照片,可以先对图片进行描述,并作为上下文传入到请求当中。
如何实现图片理解
简单图片理解
在对话过程中,如果你需要将图片传递给大模型,则可以通过在传入的信息当中,加入type 为 image_url 类型的内容,来完成对话。
阶跃星辰支持在 image_url 类型中使用 URL 或 Base64 格式的内容,为了保证更好的性能,推荐使用 URL 来完成图片参数的传递。
具体实现可以参考如下代码
基于图片的多轮对话
除了直接使用图片进行图像理解,你还可以使用图片进行多轮对话,通过将其放置在上下文中,即可完成多轮对话。 具体实现可以参考如下代码。多图图片理解
使用 detail 参数提供更加完整的信息
step-1o-turbo-vision 模型推荐默认开启 detail 模式,会拥有更好的视觉理解能力。step-1o-turbo-vision 默认每张图片约 169 token;
但在一些具体的业务场景下,需要大模型细致的理解图片中的细节和内容,则可以通过设置其 detail 模式为 high,使得大模型获取到更加完整的信息,从而进行更加详细的图片理解和描述。需要注意的是,当 detail 模式为 high 时,图片的 Token 消耗将会基于图片大小进行计算,可能会消耗远超低分辨率模式的 token 数,此外,由于大模型会看到完整版的图片,响应的首字时延也会有提升。
具体代码可参考下
需要注意的是,根据模型不同,一次多轮对话最多可以拥有不超过 10 张照片或 50 张照片。如果超过图片数量限制,可以参考超出模型图片数量上限的处理方式进行调整。
使用 Base64 进行图片理解
在一些场景下,希望大模型可以直接处理用户上传的图片,而不会再次上传至对象存储或服务当中,则可以选择在对话信息中使用 Base64 编码来传递图片内容,方便大模型理解和生成。 在使用时,你只需要提前将原本的图片连接替换为标准的 Base64 Data URL 来发起请求即可使用 Base64 进行大模型对话和理解。
- python
- Node.js
copy
| 图片后缀 | 图片类型 | 对应前缀 |
|---|---|---|
| jpg | image/jpeg | data:image/jpeg;base64, |
| png | image/png | data:image/png;base64, |
| gif | image/gif | data:image/gif;base64, |
| webp | image/webp | data:image/webp;base64, |
使用 Files API 加速图片理解
在使用图片理解时,如果传入的是外部的 URL,阶跃星辰的服务器将会请求外部 URL,获取图片内容并进行生成。生成的速度将会受到图片下载速度的影响,因此,我们推荐将图片放置在 CDN 或具有较大下载带宽的对象存储上,以便于对图片进行更快的下载。但如果你的图片需要重复使用,比如用来做 Few-shot,则可以考虑将图片使用阶跃星辰 Files API 上传至阶跃星辰文件存储服务上,以避免重复下载,产生持续的流量消耗。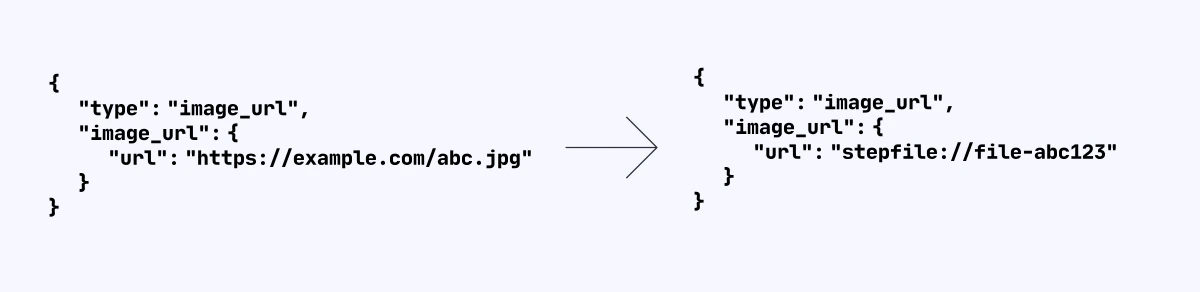
stepfile://,用于标注这个图片从阶跃星辰文件服务中获取,后续模型在推进推理时,将会从阶跃星辰文件存储服务上获取文件,从而降低下载文件所需的时间,提升整体推理的时延。
常见问题
图片较多情况下指令跟随较差的处理方式
模型在进行推理时,图片也会转换成为相应的 Image Token,当一个对话的上下文较长时,可能会导致模型重点关注靠后的 Prompt,因此在撰写 Prompt 时,可以将指令放在尾部,图片放在头部,方便模型更加关注指令,从而提升指令跟随的效果。超出模型图片数量上限的处理方式
如果在对话过程中,出现了超过模型图片上限的情况,则可以将前述的照片先使用step-3.7-flash 等多模态模型对图片进行总结和描述,并作为上下文传递。从而实现在整个对话中插入多个图片的信息。
优化图片以降低模型返回的首字延时
如果你的业务场景对于首字延时更敏感,而对于模型是否可以完整理解图片中的每一个细节,那么你可以通过对图片进行一定的预处理,以在保留绝大多数图片信息的同时,获得较好的处理速度。引入 Prompt 缓存提升推理速度
- 对图片进行 resize
- 对于 detail 设置为 low 或保持默认的情况下,可以将图片的最长边缩放至 728px,短边等比例缩放,从而提升处理的速度。
- 对于 detail 设置为 high 的情况下,可以将图片的最长边缩放至 504 的倍数,短边等比例缩放,从而提升处理的速度。
- 对图片质量进行压缩
- 通过对图片进行压缩,将其 quality 设置为 80 ,来显著降低图片大小,同时不会太过影响模型的效果。
适配透明背景的 PNG 图片
目前step-3.7-flash、step-1o-turbo-vision 等模型支持对透明背景的 PNG 图片进行处理,但在使用时,会将透明通道处理景为黑色的情况。你可以通过对图片进行处理,将其背景设置为白色,从而避免模型在推理时,无法正确理解图片中的内容。
可以参考下方代码,提前将透明背景的 PNG 图片转换成白色背景。