实现多轮对话,并管理对话上下文
大模型相比于传统的模型,拥有支持用户自定义 Prompt、用户可传入上下文等优势,从而轻松实现大模型的人设锚定、多轮对话等能力。
在实际使用时,阶跃星辰的 Chat Completion API 支持传入一个数组作为 Message List 。你只需要按照用户沟通的顺序,将用户信息和大模型返回的信息,构建成数组用于调用大模型,即可轻松实现基于大模型的多轮对话能力。
实现多轮对话
想要实现多轮对话,你需要在自己的业务系统中存储对话和对话内容,以便于形成对话记录。
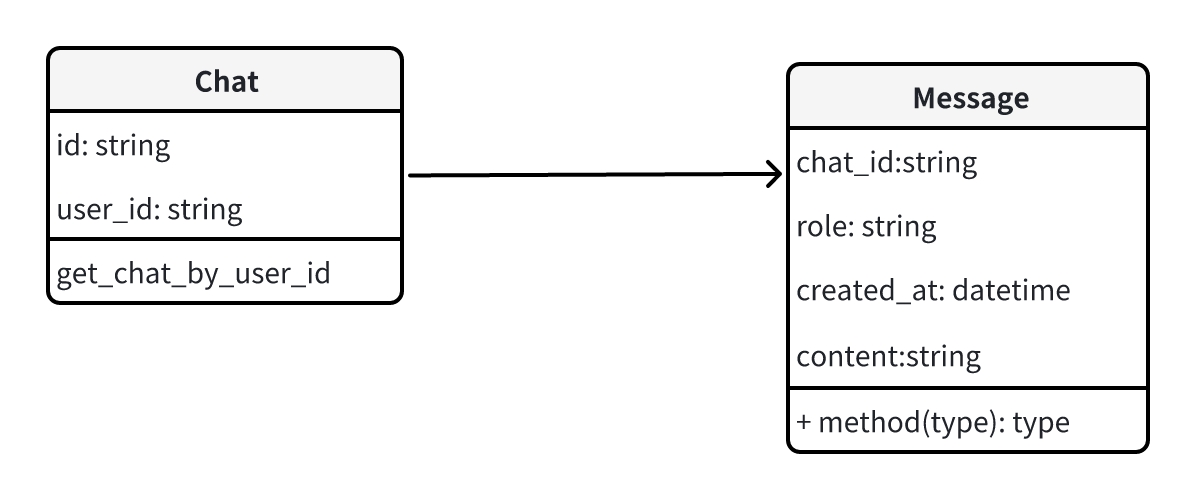
因此,你需要在业务系统中建设 Chat 和 Message 对象,并在业务系统中存储 Chat 和 Messages。
- 当用户开启对话时,则创建 Chat;
- 当用户发送消息时,则创建 Message,并按照创建时间正序查询 Message,并构建对话记录作为参数传递给大模型用于结合上下文生成内容;
- 当大模型返回信息时,同样创建 Message。
代码示例
from openai import OpenAI
from datetime import datetime
# 初始化 阶跃星辰 Client
STEPFUN_KEY = ""
client = OpenAI(
base_url="https://api.stepfun.com/v1",
api_key=STEPFUN_KEY
)
# 定义数据结构
class Chat:
id: str
user_id: str
class Message:
chat_id: str
role : str # 可选值 system, user,assistant,tool
content: str # 用户输入的信息 / 大模型返回的信息
created_at: datetime
# 从数据库中提取数据
# messages_from_db = orm.order_by ("created_at","asc").first (5)
messages_from_db = [
{
"chat_id":"chat_1",
"role":"system",
"content":"你是阶跃星辰大模型助手",
"created_at": "2024-01-01 10:01:00"
},
{
"chat_id":"chat_1",
"role":"user",
"content":"今天天气怎么样?",
"created_at": "2024-01-01 10:02:00"
},
{
"chat_id":"chat_1",
"role":"assistant",
"content":"对不起,我不能回答你关于天气的问题。",
"created_at": "2024-01-01 10:03:00"
},
{
"chat_id":"chat_1",
"role":"user",
"content":"那你告诉我北京适合去旅游么?",
"created_at": "2024-01-01 10:04:00"
}
]
def clean_msg(msg):
del msg["chat_id"]
del msg["created_at"]
return msg
messages_for_chat = [clean_msg (item) for item in messages_from_db]
# 调用补全接口进行补全
stream = client.chat.completions.create(
model="step-1-8k",
messages=messages_for_chat,
stream=True,
)
# 对流式返回的内容进行打印 / 渲染输出
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")管理对话上下文
阶跃星辰模型支持最大 256k 上下文,支持开发者将完整对话记录作为上下文传入。但对话记录也会计算整体的 Token,产生 Token 消耗,因此,建议开发者需要根据自己的业务场景选择合适的对话上下文长度发送给大模型。
-
一般日常的对话可以保留 10 轮对话记录;
-
对于某些需要深度沟通、对话的场景,则可以选择将完整对话记录交给大模型进行补全。
常见问题
- 如果要实现多轮对话的效果,需要在存储对话记录时,按时间记录,并在重新取出给大模型时,按照时间正序给出答案,以便于大模型正确的理解上下文。
Last updated on