文档解析开发指南
ℹ️
文档解析能力限时免费使用中。文件服务本身存储按 0.5元/GB/天计费。
阶跃星辰文档解析接口提供强大的文档解析能力,支持 PDF、Word 等多种格式,帮助开发者快速解析文档内容,并将其作为输入用于生成和推理。该接口提供从文档内容提取到生成应用的一站式解决方案,让基于文档内容的应用开发更加高效便捷。
效果
- 上传文件:提供文档上传接口,支持多种文档格式,简化了基于文档的内容的输入。(注意:目前仅支持纯文本内容,图片或扫描形式的文本内容暂不支持)
- 查询文件状态:文档状态查询接口让开发者及时跟踪解析进度,随时了解文档是否成功解析。
- 读取文件内容:文档解析成功后,内容提取接口可快速获得文档内容,为后续基于文档内容的生成或分析提供数据基础。
- 查询文件清单:提供文件清单查询接口,帮助开发者获取已上传文档的列表,便于文档管理。
- 删除文件:支持文件删除功能,让开发者可以在文档处理完成后随时删除文档,方便管理文档存储。
开发步骤
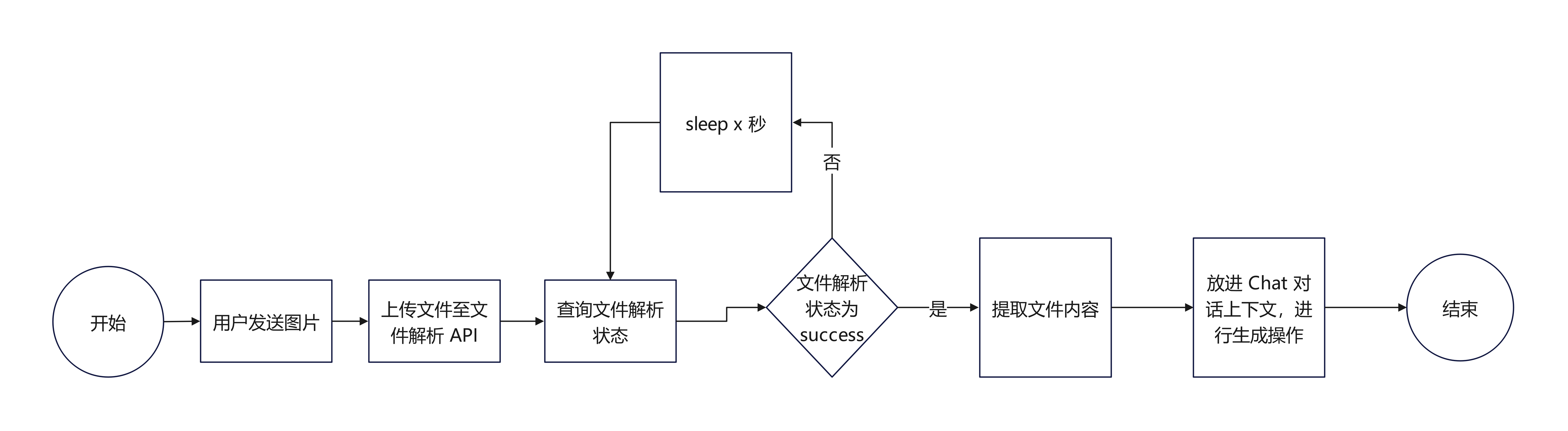
通过【上传文件】【查询文件状态】【提取文件内容】+文本补全接口 即可获得完整基于文档内容的对话补全能力
1.上传文件
上传文件到阶跃星辰文件服务,由阶跃星辰文件服务解析文件内容,用于后续生成和推理。
- 上传时使用的 purpose 字段的值为
file-extract,用于文件解析。
import requests
STEP_API_KEY="YOU_STEP_API_KEY"
BASE_URL = "https://api.stepfun.com/v1"
headers = {
"Authorization": f"Bearer {STEP_API_KEY}"
}
#定义文件名,上传本地文件
files = {
"file": ("sampleFileName.doc", open("./file/《内部审计制度》.doc", "rb")),
}
#purpose为文件使用意图字段,目前支持以下选项
#file-extract: 用作文件解析,可以将文件内的文本,解析出来。(暂时不支持图片,或扫描的文字)
#retrieval: 用于知识库,在后续上线知识库能力的时候,在知识库关联该文档的时候,会将文档字段分片并向量化,以便RAG使用
data = {
"purpose": "file-extract"
}
#调用接口上传文件
response = requests.post(BASE_URL+"/files", headers=headers, files=files, data=data)
print(response.json())
#解析出json
responseJson = response.json()
#提取出文件id
print(responseJson['id'])返回结果如下:
#返回的报文:请注意存好 id!!!!后续对文件的操作都是基于此id
{
"id": "file-C0DDg04QPg",
"object": "file",
"bytes": 56182,
"created_at": 1730194303,
"filename": "sampleFileName.doc",
"purpose": "file-extract"
}
file-C0DDg04QPg2. 查询文件状态
在文件上传完成后,需要查询文件解析状态,确认文件解析是否完成,以便后续获取文件内容。
import requests
STEP_API_KEY="YOU_STEP_API_KEY"
BASE_URL = "https://api.stepfun.com/v1"
file_id = "file-C0DDg04QPg"
URL = BASE_URL+"/files/"+file_id
headers = {
"Authorization": f"Bearer {STEP_API_KEY}"
}
response = requests.get(URL, headers=headers)
print(response.json())
#解析出json
responseJson = response.json()
#提取出文件解析的状态
print(responseJson['status'])返回结果如下,在返回的报文中重点关注status状态,当status为success时,表示文件解析处理完成,可以通过接口获取到文件的内容。
#返回的报文:重点关注status状态。
#当purpos为file-extract时。
#success:表示文件解析处理完成,可以通过接口获取到文件的内容
#processed:表示还在解析中,当前状态无法提取文件内容
{
"id": "file-C0DDg04QPg",
"object": "file",
"bytes": 56182,
"created_at": 1730194304,
"filename": "sampleFileName.doc",
"purpose": "file-extract",
"status": "success"
}
success3. 提取文件内容
当文件完成解析后,就可以使用提取文件内容接口获取文件内容,并在 Chat API 中,将内容作为对话的输入,生成对话补全。
import requests
STEP_API_KEY="YOU_STEP_API_KEY"
BASE_URL = "https://api.stepfun.com/v1"
file_id = "file-C0DDg04QPg"
URL = BASE_URL+"/files/"+file_id+"/content"
headers = {
"Authorization": f"Bearer {STEP_API_KEY}"
}
response = requests.get(URL, headers=headers)
print(response.text)
#返回的报文:解析文档后生成内容
#例如
好好学习,天天向上4. 基于文档推理完整示例
当提取到需要的文档内容后,可以将文档内容作为对话的输入,生成对话补全。完整代码参考如下
import requests
import time
from openai import OpenAI
STEP_API_KEY = "YOU_STEP_API_KEY"
BASE_URL = "https://api.stepfun.com/v1"
#定义上传文件方法
def upload_file(filename, filepath, base_url, step_api_key):
headers = {
"Authorization": f"Bearer {step_api_key}"
}
with open(filepath, "rb") as file:
files = {
"file": (filename, file),
}
data = {
"purpose": "file-extract"
}
# Make the API request
response = requests.post(f"{base_url}/files", headers=headers, files=files, data=data)
# Parse the JSON response
response_json = response.json()
# Return the file ID
return response_json.get("id")
#定义获取文件状态方法
def get_file_status(fileid, base_url, step_api_key):
headers = {
"Authorization": f"Bearer {step_api_key}"
}
url = f"{base_url}/files/{fileid}"
response = requests.get(url, headers=headers)
response_json = response.json()
return response_json.get('status', 'unknown')
#定义获取文件内容方法
def get_file_content(fileid, base_url, step_api_key):
headers = {
"Authorization": f"Bearer {step_api_key}"
}
url = f"{base_url}/files/{fileid}/content"
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return f"Error: {response.status_code} - {response.text}"
# 上传文件获取文件ID
file_id = upload_file(
filename="经济责任审计制度.doc",
filepath="./file/《经济责任审计制度》.doc",
base_url=BASE_URL,
step_api_key=STEP_API_KEY,
)
# 等待文件解析完成
while True:
status = get_file_status(file_id, BASE_URL, STEP_API_KEY)
if status == 'success':
break
time.sleep(1) # 避免频繁请求
# 获取文件内容
file_content = get_file_content(file_id, BASE_URL, STEP_API_KEY)
print(file_content)
# 生成对话
messages = [
{
"role": "system",
"content": "你是阶跃星辰助手,会读取用户发送给你的文件的内容,并结合文件内容回答问题",
},
{
"role": "user",
"content": file_content,
},
{"role": "user", "content": "请简单介绍文档的具体内容"},
]
time_start = time.time()
# 初始化
client = OpenAI(api_key=STEP_API_KEY,base_url=BASE_URL)
# 针对长文本分析,建议先使用token count接口计算一次文件解析出文本的tokens,https://platform.stepfun.com/docs/zh/api-reference/token-count,
# 再选择使用 step-1-128k 或者 step-1-256k 等超长上下文大模型
# 实现文本补全
response = client.chat.completions.create(
messages=messages,
model="step-1-128k",
stream=True,
)
i=0
for chunk in response:
i += 1
print(chunk.choices[0].delta.content.strip(),end="")
if i == 1:
time_firstWord = time.time()
elapsed_time= time_firstWord-time_start
print(f"首字生成时间: {elapsed_time:.2f} 秒")
time_end = time.time()
elapsed_time = time_end - time_start
print(f"总生成时间: {elapsed_time:.2f} 秒")
#返回的报文:即针对文件解析出来的内容生成的会话补全内容其他操作实例
查看文件列表
import requests
STEP_API_KEY="YOU_STEP_API_KEY"
BASE_URL = "https://api.stepfun.com/v1"
#filePurpose根据需要填写file-extract或retrieval
filePurpose="file-extract"
URL = BASE_URL+"/files?purpose="+filePurpose
headers = {
"Authorization": f"Bearer {STEP_API_KEY}"
}
response = requests.get(URL, headers=headers)
responseJson = response.json()
print(responseJson)返回结果如下:
#返回的报文,将会列举出上传成功的文件清单。
#建议将文件清单读取后,缓存到页面上,以便于对文档进行操作
{
"object": "list",
"data": [
{
"id": "file-C0OBldwum0",
"object": "file",
"bytes": 1095573,
"created_at": 1730203514,
"filename": "繁花.txt",
"purpose": "file-extract",
"status": "success"
},
{
"id": "file-C0OGG69uvw",
"object": "file",
"bytes": 60728,
"created_at": 1730203574,
"filename": "经济责任审计制度.doc",
"purpose": "file-extract",
"status": "success"
}
]
}删除文件
import requests
STEP_API_KEY="YOU_STEP_API_KEY"
BASE_URL = "https://api.stepfun.com/v1"
file_id = "file-C0OGG69uvw"
URL = BASE_URL+"/files/"+file_id
headers = {
"Authorization": f"Bearer {STEP_API_KEY}"
}
response = requests.delete(URL, headers=headers)
responseJson = response.json()
print(responseJson)
返回结果如下:
#返回的报文,将会告知是否删除成功。
{
"id": "file-C0OGG69uvw",
"object": "file",
"deleted": true
}注意事项
- 文件解析流程:
- 对于首次解析的文件,需先查询文件解析状态,确认成功后再获取内容。
- 超长文本解析时,请先计算内容的 tokens 数量,以避免超出限制导致的请求中断。
- 文件与请求限制:
- 单文件大小:最大 64MB。
- 文件总数限制:最多存储 1000 个文件。
- 支持的意图:
- file-extract:用于文档内容解析。
- retrieval:用于知识库存储。
- 支持的文件类型:
- 纯文本文件:.txt, .md
- PDF 文件:.pdf
- Word 文档:.doc, .docx
- Excel 表格:.xls, .xlsx
- PPT 文件:.ppt, .pptx
- CSV 文件:.csv
- HTML/XML 文件:.html, .htm, .xml
- 内容限制:
- 仅支持纯文本内容解析,不支持图片或扫描的文本内容。
Last updated on