> ## Documentation Index
> Fetch the complete documentation index at: https://platform.stepfun.com/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# 图片理解最佳实践
阶跃星辰视觉理解大模型支持在对话过程中传入图片文件用于理解图片当中的内容,参与大模型的对话过程中,通过图像来补充上下文,以实现诸如:基于图片追问、提问图片中的内容等能力。
目前推荐使用 `step-1o-turbo-vision` 模型。该模型拥有最强的视频理解能力,推荐默认开启 detail 模式。
## 能力限制
* 目前 `step-3.7-flash`、`step-1o-turbo-vision` 等模型支持 JPG/JPEG、PNG、静态 GIF、WebP 格式的图片,且支持通过 URL 或 Base64 作为参数传递。
* 上述模型限制了单次请求图像不能超过 60 张,如果超过 60 张照片,可以先对图片进行描述,并作为上下文传入到请求当中。
## 如何实现图片理解
### 简单图片理解
在对话过程中,如果你需要将图片传递给大模型,则可以通过在传入的信息当中,加入 `type` 为 `image_url` 类型的内容,来完成对话。
阶跃星辰支持在 image\_url 类型中使用 URL 或 Base64 格式的内容,为了保证更好的性能,推荐使用 URL 来完成图片参数的传递。
具体实现可以参考如下代码
```python theme={null}
from openai import OpenAI
import os
API_KEY= os.getenv("API_KEY")
client = OpenAI(api_key=API_KEY, base_url="https://api.stepfun.com/v1")
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
# 在对话中传入图片,来实现基于图片的理解
{
"role": "user",
"content": [
{
"type": "text",
"text": "用优雅的语言描述这张图片",
},
{
"type": "image_url",
"image_url": {
"url": "https://www.stepfun.com/assets/section-1-CTe4nZiO.webp",
"detail": "high"
},
},
],
},
],
)
print(completion.model_dump_json(indent=3))
# 输出内容
# {
# "id": "105e9027276481c141821b77b1b2a2f2.eeb4fc6f4b4e39921fe5fc5e2f33d57c",
# "choices": [
# {
# "finish_reason": "stop",
# "index": 0,
# "logprobs": null,
# "message": {
# "content": "在这幅静谧的夜景中,一座现代建筑在微光中显得格外引人注目。建筑外墙上“ART WEST BUND”的字样在灯光的映衬下熠熠生辉,透露出浓厚的艺术气息。建筑前的广场宽敞而整洁,几盏路灯散发出温暖的光芒,为夜色增添了一丝浪漫。树木静静地矗立在广场上,仿佛在守护着这片宁静的艺术之地。远处的高楼在夜幕中若隐若现,与这座艺术殿堂相映成趣,共同构成了一幅充满现代感与艺术气息的都市夜景图。",
# "refusal": null,
# "role": "assistant",
# "function_call": null,
# "tool_calls": null
# }
# }
# ],
# "created": 1727073234,
# "model": "step-1o-turbo-vision",
# "object": "chat.completion",
# "service_tier": null,
# "system_fingerprint": null,
# "usage": {
# "completion_tokens": 130,
# "prompt_tokens": 497,
# "total_tokens": 627,
# "completion_tokens_details": null,
# "cached_tokens": 256
# }
# }
```
### 基于图片的多轮对话
除了直接使用图片进行图像理解,你还可以使用图片进行多轮对话,通过将其放置在上下文中,即可完成多轮对话。
具体实现可以参考如下代码。
```python theme={null}
from openai import OpenAI
import os
API_KEY= os.getenv("API_KEY")
client = OpenAI(api_key=API_KEY, base_url="https://api.stepfun.com/v1")
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "用优雅的语言描述这张图片",
},
{
"type": "image_url",
"image_url": {
"url": "https://www.stepfun.com/assets/section-1-CTe4nZiO.webp",
"detail": "high"
},
},
],
},
# 将模型给予的返回重新插入会对话上下文,进行一轮新的对话
{
"role":"assistant",
"content": "这幅图片中,我们看到了一座现代建筑,它坐落在一个宁静而宽敞的广场上。建筑的外墙以简洁的线条和明亮的色彩为特色,彰显出一种现代美学。夜幕降临,天空呈现出淡淡的蓝色,与建筑的暖色灯光形成了鲜明的对比,营造出一种温馨而宁静的氛围。\n\n广场上,几盏路灯散发出柔和的光芒,为周围的树木和地面铺上了一层温暖的光辉。树木静静地矗立在广场上,为这座建筑增添了一丝自然的气息。远处的高楼大厦在夜色中若隐若现,与这座建筑形成了鲜明的对比,展现出城市的繁华与宁静并存的景象。\n\n总的来说,这幅图片通过巧妙的构图和色彩运用,展现了一座现代建筑在夜幕中的美丽景象,让人感受到城市中的宁静与温馨。"
},
# 将用户的新问题继续追问大模型
{
"role":"user",
"content":"那这张照片可能是在哪个国家拍摄的?"
}
],
)
print(completion.model_dump_json(indent=3))
# 输出内容
# {
# "id": "aad5d20afc7506cfda8fc7510124d948.05ca5a939a04585bd7a68e5a9ee64563",
# "choices": [
# {
# "finish_reason": "stop",
# "index": 0,
# "logprobs": null,
# "message": {
# "content": "这张照片展示了一座现代建筑,建筑外墙上写有“ART WEST BUND”的字样,这通常是上海西岸艺术中心的标志。上海西岸艺术中心位于中国上海,是一处集艺术展览、文化交流和休闲娱乐于一体的综合性艺术园区。因此,这张照片很可能是在中国上海拍摄的。",
# "refusal": null,
# "role": "assistant",
# "function_call": null,
# "tool_calls": null
# }
# }
# ],
# "created": 1727073254,
# "model": "step-1o-turbo-vision",
# "object": "chat.completion",
# "service_tier": null,
# "system_fingerprint": null,
# "usage": {
# "completion_tokens": 65,
# "prompt_tokens": 697,
# "total_tokens": 762,
# "completion_tokens_details": null,
# "cached_tokens": 256
# }
# }
```
### 多图图片理解
### 使用 detail 参数提供更加完整的信息
`step-1o-turbo-vision` 模型推荐默认开启 detail 模式,会拥有更好的视觉理解能力。
目前默认会选择低分辨率模式,以获得更加快速响应速度,同时,低分辨率模式也会带来较少的 token 消耗。在低分辨率模式下,`step-1o-turbo-vision` 默认每张图片约 169 token;
但在一些具体的业务场景下,需要大模型细致的理解图片中的细节和内容,则可以通过设置其 detail 模式为 `high`,使得大模型获取到更加完整的信息,从而进行更加详细的图片理解和描述。需要注意的是,当 detail 模式为 `high` 时,图片的 Token 消耗将会基于图片大小进行计算,可能会消耗远超低分辨率模式的 token 数,此外,由于大模型会看到完整版的图片,响应的首字时延也会有提升。
具体代码可参考下
```python theme={null}
from openai import OpenAI
import os
API_KEY= os.getenv("API_KEY")
client = OpenAI(api_key=API_KEY, base_url="https://api.stepfun.com/v1")
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
# 在对话中传入图片,来实现基于图片的理解
{
"role": "user",
"content": [
{
"type": "text",
"text": "用优雅的语言描述这张照片",
},
{
"type": "image_url",
"image_url": {
"url": "https://www.stepfun.com/assets/section-1-CTe4nZiO.webp"
},
},
{
"type":"image_url",
"image_url":{
"url":"https://postimg.aliavv.com/step/daesog.png"
}
}
],
},
],
)
print("low detail")
print(completion.model_dump_json(indent=2))
print("high detail")
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "用优雅的语言描述这张照片",
},
{
"type":"image_url",
"image_url":{
"url":"https://postimg.aliavv.com/step/daesog.png",
"detail":"high"
}
}
],
},
],
)
print(completion.model_dump_json(indent=2))
# 输出内容
# low detail
# {
# "id": "3f4db73a6d12292f6a4ca78b9811bcc5.9cad450fae99f56ba0e269e6185981ef",
# "choices": [
# {
# "finish_reason": "stop",
# "index": 0,
# "logprobs": null,
# "message": {
# "content": "这张照片展现了一座现代化城市的壮丽夜景。从高处俯瞰,城市的天际线在夜幕中熠熠生辉,高楼大厦的灯光如繁星点点,勾勒出一幅繁华而迷人的画卷。蜿蜒的河流贯穿城市,水面反射着两岸的灯火,宛如一条闪耀的丝带。照片中的建筑各具特色,有的高耸入云,有的独具匠心,共同谱写出一曲都市的交响乐。夜色中的城市,充满了活力与魅力,让人不禁为之沉醉。",
# "refusal": null,
# "role": "assistant",
# "function_call": null,
# "tool_calls": null
# }
# }
# ],
# "created": 1727073489,
# "model": "step-1o-turbo-vision",
# "object": "chat.completion",
# "service_tier": null,
# "system_fingerprint": null,
# "usage": {
# "completion_tokens": 117,
# "prompt_tokens": 899,
# "total_tokens": 1016,
# "completion_tokens_details": null
# }
# }
# high detail
# {
# "id": "cb3b1fb0f8e7aeb4caa096ec235b494e.f2bbc7d720611275241dd62954fb3b19",
# "choices": [
# {
# "finish_reason": "stop",
# "index": 0,
# "logprobs": null,
# "message": {
# "content": "在这幅照片中,我们俯瞰着一座繁华的城市,夜幕低垂,万家灯火如星辰般点缀着大地。高楼大厦拔地而起,宛如巨人般屹立在城市的心脏,勾勒出一幅现代与传统的完美融合画卷。河流蜿蜒流过城市,水面反射着璀璨的灯光,宛如一条银色的丝带,将城市的繁华与宁静巧妙地连接在一起。\n\n照片中,东方明珠电视塔高耸入云,成为城市的标志性建筑,其独特的造型在夜色中熠熠生辉。周围的建筑也纷纷点亮了灯光,犹如一座座灯塔,指引着夜归的人们。街道上车水马龙,流光溢彩,仿佛一条条流动的银河,为这座城市增添了无限的活力与魅力。\n\n在这幅照片中,我们不仅看到了城市的繁华与喧嚣,更感受到了一种宁静与和谐。它让我们明白,无论城市多么喧嚣,总有一片宁静的港湾等待着我们去发现。",
# "refusal": null,
# "role": "assistant",
# "function_call": null,
# "tool_calls": null
# }
# }
# ],
# "created": 1727073505,
# "model": "step-1o-turbo-vision",
# "object": "chat.completion",
# "service_tier": null,
# "system_fingerprint": null,
# "usage": {
# "completion_tokens": 217,
# "prompt_tokens": 2102,
# "total_tokens": 2319,
# "completion_tokens_details": null
# }
# }
```
如果你需要在对话过程中,使用多个图片,则可以在对话过程中通过 image\_url 传入多个图片来完成对话和问答。
> 需要注意的是,根据模型不同,一次多轮对话最多可以拥有不超过 10 张照片或 50 张照片。如果超过图片数量限制,可以参考[超出模型图片数量上限的处理方式](/zh/guides/developer/image-chat#超出模型图片数量上限的处理方式)进行调整。
```python theme={null}
from openai import OpenAI
import os
API_KEY= os.getenv("API_KEY")
client = OpenAI(api_key=API_KEY, base_url="https://api.stepfun.com/v1")
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
# 在对话中传入图片,来实现基于图片的理解
{
"role": "user",
"content": [
{
"type": "text",
"text": "用优雅的语言描述这两张照片",
},
{
"type": "image_url",
"image_url": {
"url": "https://www.stepfun.com/assets/section-1-CTe4nZiO.webp",
"detail": "high"
},
},
{
"type":"image_url",
"image_url":{
"url":"https://postimg.aliavv.com/step/daesog.png",
"detail":"high"
}
}
],
},
],
)
print(completion.model_dump_json(indent=3))
# 输出内容
# {
# "id": "dd2937ea8d72e0a5064826e2f0154c02.1e83c144d202624be954996ef3fa3a5c",
# "choices": [
# {
# "finish_reason": "stop",
# "index": 0,
# "logprobs": null,
# "message": {
# "content": "第一张照片展现了一座现代建筑,其设计简洁而富有现代感。在黄昏的柔和光线下,建筑外墙的浅色与周围环境形成了和谐的对比。入口处的红色设计引人注目,仿佛是这座建筑的心脏,散发着温暖的光芒。周围的树木和灯光点缀其间,为整个场景增添了一丝宁静与优雅。地面的石材铺装和远处的阶梯设计,使空间显得更加开阔和有层次感。\n\n第二张照片则展示了一座繁华都市的夜景,从高空俯瞰,城市的灯火辉煌尽收眼底。高楼大厦错落有致,灯光璀璨,犹如星河倒映在人间。河流蜿蜒穿过城市,水面反射着两岸的霓虹,为这座城市增添了一份流动的韵律。夜色中的城市充满了活力与魅力,每一栋建筑都仿佛在诉说着自己的故事,共同谱写出一曲繁华的乐章。",
# "refusal": null,
# "role": "assistant",
# "function_call": null,
# "tool_calls": null
# }
# }
# ],
# "created": 1727073194,
# "model": "step-1o-turbo-vision",
# "object": "chat.completion",
# "service_tier": null,
# "system_fingerprint": null,
# "usage": {
# "completion_tokens": 193,
# "prompt_tokens": 900,
# "total_tokens": 1093,
# "completion_tokens_details": null,
# "cached_tokens": 768
# }
# }
```
在上述对话过程中,通过在 content 当中传入多个图片的 image\_url,实现了在对话中使用多张图片来进行问答。你可以根据实际情况,将多个图片插入到多个消息当中,或保留在同一个消息当中。
### 使用 Base64 进行图片理解
在一些场景下,希望大模型可以直接处理用户上传的图片,而不会再次上传至对象存储或服务当中,则可以选择在对话信息中使用 Base64 编码来传递图片内容,方便大模型理解和生成。
在使用时,你只需要提前将原本的图片连接替换为标准的 Base64 [Data URL](https://www.rfc-editor.org/rfc/rfc2397) 来发起请求即可使用 Base64 进行大模型对话和理解。
 你可以参考如下代码对图片处理,获得图片对应的 Base64 文本,并拼接到 Chat 中
```python copy theme={null}
import base64
with open("./sample.jpg", "rb") as image_file:
base64_bytes = base64.b64encode(image_file.read())
print(base64_bytes)
```
```js copy theme={null}
const fs = require('fs');
const imageBuffer = fs.readFileSync('./sample.jpg');
const base64Image = imageBuffer.toString('base64');
console.log(base64Image)
```
需要注意的是,上述方法获得的是图片的 bas64 编码,在实际调用时,你还需要拼上对应格式的类型等信息,常见图片类型的对应前缀可参考如下表格。
| 图片后缀 | 图片类型 | 对应前缀 |
| ---- | ---------- | ------------------------- |
| jpg | image/jpeg | `data:image/jpeg;base64,` |
| png | image/png | `data:image/png;base64,` |
| gif | image/gif | `data:image/gif;base64,` |
| webp | image/webp | `data:image/webp;base64,` |
### 使用 Files API 加速图片理解
在使用图片理解时,如果传入的是外部的 URL,阶跃星辰的服务器将会请求外部 URL,获取图片内容并进行生成。生成的速度将会受到图片下载速度的影响,因此,我们推荐将图片放置在 CDN 或具有较大下载带宽的对象存储上,以便于对图片进行更快的下载。但如果你的图片需要重复使用,比如用来做 Few-shot,则可以考虑将图片使用阶跃星辰 Files API 上传至阶跃星辰文件存储服务上,以避免重复下载,产生持续的流量消耗。
你可以参考如下代码对图片处理,获得图片对应的 Base64 文本,并拼接到 Chat 中
```python copy theme={null}
import base64
with open("./sample.jpg", "rb") as image_file:
base64_bytes = base64.b64encode(image_file.read())
print(base64_bytes)
```
```js copy theme={null}
const fs = require('fs');
const imageBuffer = fs.readFileSync('./sample.jpg');
const base64Image = imageBuffer.toString('base64');
console.log(base64Image)
```
需要注意的是,上述方法获得的是图片的 bas64 编码,在实际调用时,你还需要拼上对应格式的类型等信息,常见图片类型的对应前缀可参考如下表格。
| 图片后缀 | 图片类型 | 对应前缀 |
| ---- | ---------- | ------------------------- |
| jpg | image/jpeg | `data:image/jpeg;base64,` |
| png | image/png | `data:image/png;base64,` |
| gif | image/gif | `data:image/gif;base64,` |
| webp | image/webp | `data:image/webp;base64,` |
### 使用 Files API 加速图片理解
在使用图片理解时,如果传入的是外部的 URL,阶跃星辰的服务器将会请求外部 URL,获取图片内容并进行生成。生成的速度将会受到图片下载速度的影响,因此,我们推荐将图片放置在 CDN 或具有较大下载带宽的对象存储上,以便于对图片进行更快的下载。但如果你的图片需要重复使用,比如用来做 Few-shot,则可以考虑将图片使用阶跃星辰 Files API 上传至阶跃星辰文件存储服务上,以避免重复下载,产生持续的流量消耗。
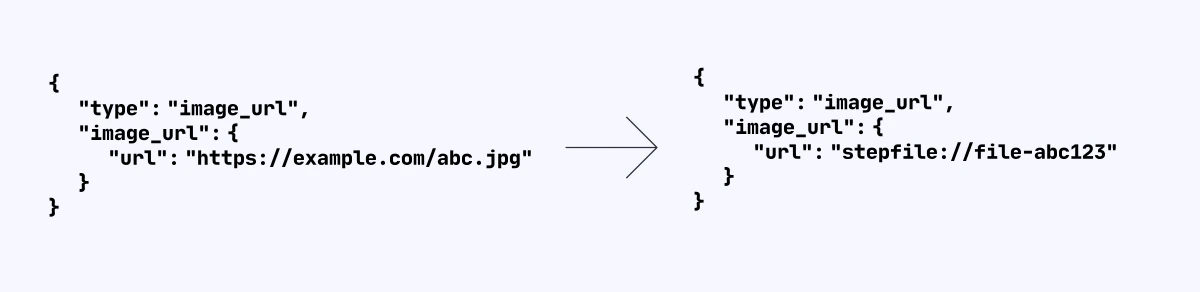 你可以调用[上传文件](/zh/api-reference/files/create) API,并传入文件,选择 **purpose 为 storage**,上传完成后所获取的 File ID 则可以在对话过程中使用。在拿到 File ID 后,你需要在 File ID 前拼上 `stepfile://`,用于标注这个图片从阶跃星辰文件服务中获取,后续模型在推进推理时,将会从阶跃星辰文件存储服务上获取文件,从而降低下载文件所需的时间,提升整体推理的时延。
## 常见问题
### 图片较多情况下指令跟随较差的处理方式
模型在进行推理时,图片也会转换成为相应的 Image Token,当一个对话的上下文较长时,可能会导致模型重点关注靠后的 Prompt,因此在撰写 Prompt 时,可以将指令放在尾部,图片放在头部,方便模型更加关注指令,从而提升指令跟随的效果。
### 超出模型图片数量上限的处理方式
如果在对话过程中,出现了超过模型图片上限的情况,则可以将前述的照片先使用 `step-3.7-flash` 等多模态模型对图片进行总结和描述,并作为上下文传递。从而实现在整个对话中插入多个图片的信息。
```python theme={null}
from openai import OpenAI
import os
API_KEY= os.getenv("API_KEY")
client = OpenAI(api_key=API_KEY, base_url="https://api.stepfun.com/v1")
# 使用 `step-1o-turbo-vision` 模型,对图片进行描述
def get_description_from_img(img_url:str):
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
# 在对话中传入图片,来实现基于图片的理解
{
"role": "user",
"content": [
{
"type": "text",
"text": "请详细描述这张图片中的内容",
},
{
"type": "image_url",
"image_url": {
"url": img_url,
"detail":"high"
},
},
],
},
],
)
return completion.choices[0].message.content
real_chat_context = []
real_chat_context.append({
"role": "user",
"content": get_description_from_img("https://www.stepfun.com/assets/section-1-CTe4nZiO.webp"),
})
print(real_chat_context)
# 调用模型进行真正的对话沟通。
```
### 优化图片以降低模型返回的首字延时
如果你的业务场景对于首字延时更敏感,而对于模型是否可以完整理解图片中的每一个细节,那么你可以通过对图片进行一定的预处理,以在保留绝大多数图片信息的同时,获得较好的处理速度。
{' '}
* 对图片进行 resize
* 对于 detail 设置为 low 或保持默认的情况下,可以将图片的最长边缩放至 728px,短边等比例缩放,从而提升处理的速度。
* 对于 detail 设置为 high 的情况下,可以将图片的最长边缩放至 504 的倍数,短边等比例缩放,从而提升处理的速度。
* 对图片质量进行压缩
* 通过对图片进行压缩,将其 quality 设置为 80 ,来显著降低图片大小,同时不会太过影响模型的效果。
```python theme={null}
from PIL import Image
# 确保安装了Pillow库
# 运行以下命令以安装Pillow
# pip install Pillow
# 处理图片为 80% 质量
def compress(input_path, output_path, quality):
image = Image.open(input_path)
image.save(output_path, quality=quality)
# 将图片按照最长边resize到728,短边等比例缩放,并存储为新图片
def resize_image(input_path, output_path, max_size):
image = Image.open(input_path)
width, height = image.size
# 计算新的尺寸
if width > height:
new_width = max_size
new_height = int((max_size / width) * height)
else:
new_height = max_size
new_width = int((max_size / height) * width)
# 调整图片尺寸
resized_image = image.resize((new_width, new_height), Image.ANTIALIAS)
resized_image.save(output_path)
# 调用函数
resize_image('input.jpg', 'resized_output.jpg', 728)
compress('input.jpg', 're_quality_output.jpg',80)
```
### 适配透明背景的 PNG 图片
目前 `step-3.7-flash`、`step-1o-turbo-vision` 等模型支持对透明背景的 PNG 图片进行处理,但在使用时,会将透明通道处理景为黑色的情况。你可以通过对图片进行处理,将其背景设置为白色,从而避免模型在推理时,无法正确理解图片中的内容。
可以参考下方代码,提前将透明背景的 PNG 图片转换成白色背景。
```python theme={null}
from PIL import Image
def convert_rgba_to_rgb_with_white_background(input_path, output_path):
img = Image.open(input_path)
if img.mode != 'RGBA':
raise ValueError("输入图片不是 RGBA 模式")
white_background = Image.new('RGB', img.size, (255, 255, 255))
white_background.paste(img, mask=img.split()[3])
result = white_background.convert("RGB")
result.save(output_path)
```
你可以调用[上传文件](/zh/api-reference/files/create) API,并传入文件,选择 **purpose 为 storage**,上传完成后所获取的 File ID 则可以在对话过程中使用。在拿到 File ID 后,你需要在 File ID 前拼上 `stepfile://`,用于标注这个图片从阶跃星辰文件服务中获取,后续模型在推进推理时,将会从阶跃星辰文件存储服务上获取文件,从而降低下载文件所需的时间,提升整体推理的时延。
## 常见问题
### 图片较多情况下指令跟随较差的处理方式
模型在进行推理时,图片也会转换成为相应的 Image Token,当一个对话的上下文较长时,可能会导致模型重点关注靠后的 Prompt,因此在撰写 Prompt 时,可以将指令放在尾部,图片放在头部,方便模型更加关注指令,从而提升指令跟随的效果。
### 超出模型图片数量上限的处理方式
如果在对话过程中,出现了超过模型图片上限的情况,则可以将前述的照片先使用 `step-3.7-flash` 等多模态模型对图片进行总结和描述,并作为上下文传递。从而实现在整个对话中插入多个图片的信息。
```python theme={null}
from openai import OpenAI
import os
API_KEY= os.getenv("API_KEY")
client = OpenAI(api_key=API_KEY, base_url="https://api.stepfun.com/v1")
# 使用 `step-1o-turbo-vision` 模型,对图片进行描述
def get_description_from_img(img_url:str):
completion = client.chat.completions.create(
model="step-1o-turbo-vision",
messages=[
{
"role": "system",
"content": "你是由阶跃星辰提供的AI聊天助手,你除了擅长中文,英文,以及多种其他语言的对话以外,还能够根据用户提供的图片,对内容进行精准的内容文本描述。在保证用户数据安全的前提下,你能对用户的问题和请求,作出快速和精准的回答。同时,你的回答和建议应该拒绝黄赌毒,暴力恐怖主义的内容",
},
# 在对话中传入图片,来实现基于图片的理解
{
"role": "user",
"content": [
{
"type": "text",
"text": "请详细描述这张图片中的内容",
},
{
"type": "image_url",
"image_url": {
"url": img_url,
"detail":"high"
},
},
],
},
],
)
return completion.choices[0].message.content
real_chat_context = []
real_chat_context.append({
"role": "user",
"content": get_description_from_img("https://www.stepfun.com/assets/section-1-CTe4nZiO.webp"),
})
print(real_chat_context)
# 调用模型进行真正的对话沟通。
```
### 优化图片以降低模型返回的首字延时
如果你的业务场景对于首字延时更敏感,而对于模型是否可以完整理解图片中的每一个细节,那么你可以通过对图片进行一定的预处理,以在保留绝大多数图片信息的同时,获得较好的处理速度。
{' '}
* 对图片进行 resize
* 对于 detail 设置为 low 或保持默认的情况下,可以将图片的最长边缩放至 728px,短边等比例缩放,从而提升处理的速度。
* 对于 detail 设置为 high 的情况下,可以将图片的最长边缩放至 504 的倍数,短边等比例缩放,从而提升处理的速度。
* 对图片质量进行压缩
* 通过对图片进行压缩,将其 quality 设置为 80 ,来显著降低图片大小,同时不会太过影响模型的效果。
```python theme={null}
from PIL import Image
# 确保安装了Pillow库
# 运行以下命令以安装Pillow
# pip install Pillow
# 处理图片为 80% 质量
def compress(input_path, output_path, quality):
image = Image.open(input_path)
image.save(output_path, quality=quality)
# 将图片按照最长边resize到728,短边等比例缩放,并存储为新图片
def resize_image(input_path, output_path, max_size):
image = Image.open(input_path)
width, height = image.size
# 计算新的尺寸
if width > height:
new_width = max_size
new_height = int((max_size / width) * height)
else:
new_height = max_size
new_width = int((max_size / height) * width)
# 调整图片尺寸
resized_image = image.resize((new_width, new_height), Image.ANTIALIAS)
resized_image.save(output_path)
# 调用函数
resize_image('input.jpg', 'resized_output.jpg', 728)
compress('input.jpg', 're_quality_output.jpg',80)
```
### 适配透明背景的 PNG 图片
目前 `step-3.7-flash`、`step-1o-turbo-vision` 等模型支持对透明背景的 PNG 图片进行处理,但在使用时,会将透明通道处理景为黑色的情况。你可以通过对图片进行处理,将其背景设置为白色,从而避免模型在推理时,无法正确理解图片中的内容。
可以参考下方代码,提前将透明背景的 PNG 图片转换成白色背景。
```python theme={null}
from PIL import Image
def convert_rgba_to_rgb_with_white_background(input_path, output_path):
img = Image.open(input_path)
if img.mode != 'RGBA':
raise ValueError("输入图片不是 RGBA 模式")
white_background = Image.new('RGB', img.size, (255, 255, 255))
white_background.paste(img, mask=img.split()[3])
result = white_background.convert("RGB")
result.save(output_path)
```